关于Pony_OCR的说明
这是一个关于OCR识别应用在植物图片上的小项目(草本植物OCR助手)。
架构设计
前后端分离
1、前端采用vue3 搭建,用于展示图片和识别的效果。
放在服务器上的版本原型图如下:
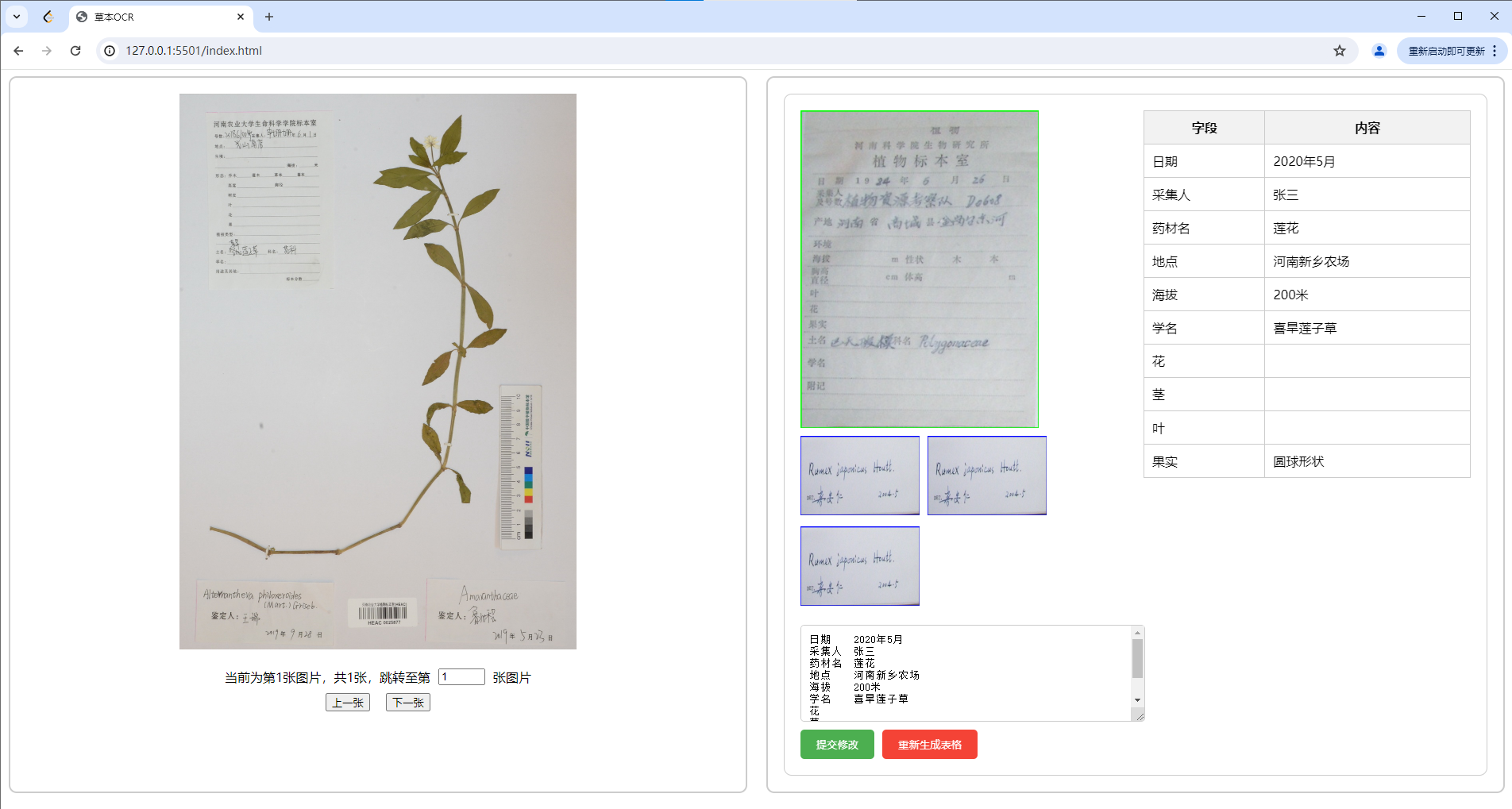
左侧为原始的图片,通过导航栏进行切换和跳转;右侧为进行各种处理后的状态展示,分别是分割的状态,文字提取的状态,转化成表格的状态。
- 待添加服务器版本链接
2、后端使用python+flask框架搭建rest服务的形式。分别做了截取文本框,检测文本,文本转表格等服务。
前端具体实现
这是一个单页面应用,经构思后补充了些功能,再顶部再增加一个区域(包含原始数据图片所在的路径,和一个处理结果输出路径,一个run all按钮),run all按钮将执行图片分割、文本提取与转化、生成Excel等一系列操作。处理的过程中会有进度条显示出来。本站提供的演示版本不支持用户选择路径,因为用的是服务器后台的数据,不做上传文件的功能。但本地版是支持用户选择图片集路径的。
vite + vue + element plus 搭建如下界面:
- 待完成
vue逻辑部分编写
- 图片路径设置
- 图片轮播功能
- 文本框编辑逻辑
- 表格交互逻辑
- REST交互
训练yolo进行图片分割
- 已完成
- 记录一版形成教程,单独的post,怎么快速配置,打标签,与训练
如何使用yolov5训练数据–极简教程
训练OCR手写文字识别
- 待完成
- python 3.11 windows平台下,ppocrlabel原版最多只在2.7版本源码里;
- paddleocr pip安装了2.10当前最新版;
- torch和torchAudio需要安装2.2.2版本;
- 记录一版形成教程,单独的post,怎么快速配置,打标签,与训练
后台服务的具体实现
- batch_yolo服务
- 已完成
- batch_ocr服务
- 已完成
- deepseek文本整合服务
- 待验证
关于版本管理
- 使用git维护client和server端代码
- 已完成
- 待验证 图片数据集的存储有两种合适的方案
- 使用制品仓库 –需要打包再上传,本地维护一份比较困难,但对于特别大的几个G的数据集合适用该方法。
- 使用lfs大文件 –将图片格式作为大文件lfs一种,通过git lfs上传。这种适合适合本地维护。